





Read article
Data engineering & AI
Turning your data into something your product and team can trust
Production-ready AI
Pipelines that don't break
Engineering, not magic
AI is an engineering problem, not a magic trick
Most companies know solid data is the foundation of everything from reporting to AI. But getting there is tough. We've seen it all: models stuck in Jupyter notebooks that never reach production, too much time spent cleaning spreadsheets, and pipelines that keep breaking.
From notebook to production
We get models into production, build pipelines that don't fall over, and clean up the data layer so your team can focus on the work that matters. We bring proper engineering practices so everyone can work with it.
Real AI, real impact
When you're ready to integrate LLMs into your product or build AI agents that actually do something useful, we take you from “we'd like to do something with AI” to “customers rely on this every day”. The right decisions early: data architecture, ML infrastructure, and tooling your team will actually maintain.
Concrete outcomes, not just code
We focus on delivering measurable improvements across four key areas that matter most to your product and team.

Data pipelines that work
Ingestion that does not lie. Pipelines that run everywhere, not just on your laptop. QA gates that catch issues before they contaminate your roadmap.
Discover moreReady to talk?
Ready to stop fighting your data infrastructure?

Classic machine learning
When you need prediction, classification or recommendation, we help you choose the right approach, build the training pipeline and deploy models that actually work in production.
Discover moreReady to talk?
Want to put proven ML to work for your product?

RAG & LLM systems
If your product needs real-time knowledge or smart retrieval over messy corpora, we build RAG systems, vector databases, hybrid search and evaluation loops that work outside the demo.
Discover moreReady to talk?
Looking to build AI features that work beyond the demo?

Monitoring & drift detection
We treat retrieval quality with the same seriousness as data quality: measurable, monitored, never hand-waved just because the prototype looked clever.
Discover moreReady to talk?
Want confidence that your models keep performing in production?
Our approach
“We bring proper engineering practices so everyone can work with it. By getting stuck in alongside your engineers, we turn messy data into something you can rely on.”
Why companies call us in
Models stuck in notebooks? Pipelines that keep breaking? Wondering how to actually get AI into your product? You're not alone.

“Releasing a new version takes an entire afternoon.”

“Rolling out new features takes too long.”

“In the early days, we had a hard time understanding the technical implications of the choices we wanted to make, which made prioritisation difficult. Madewithlove made a huge difference. What they bro…”
Ahmed Abdullah, Machine Learning Engineer at MinersAI

“Our frontend is a mess and nobody wants to touch it.”

“Our AI prototype works in a notebook but not in production.”

“Madewithlove not only helped us scale our output, but also our strategy, processes and culture. Not by imposing, but by reinforcing the foundations that were already there.”
Michelle Dassen, Head of Product at Flexmail

“My developers are not working together.”
“We’re scaling faster than our processes.”
Happy clients
We work with companies that want to get their data and AI right. Here are examples of how our approach translated into real results.
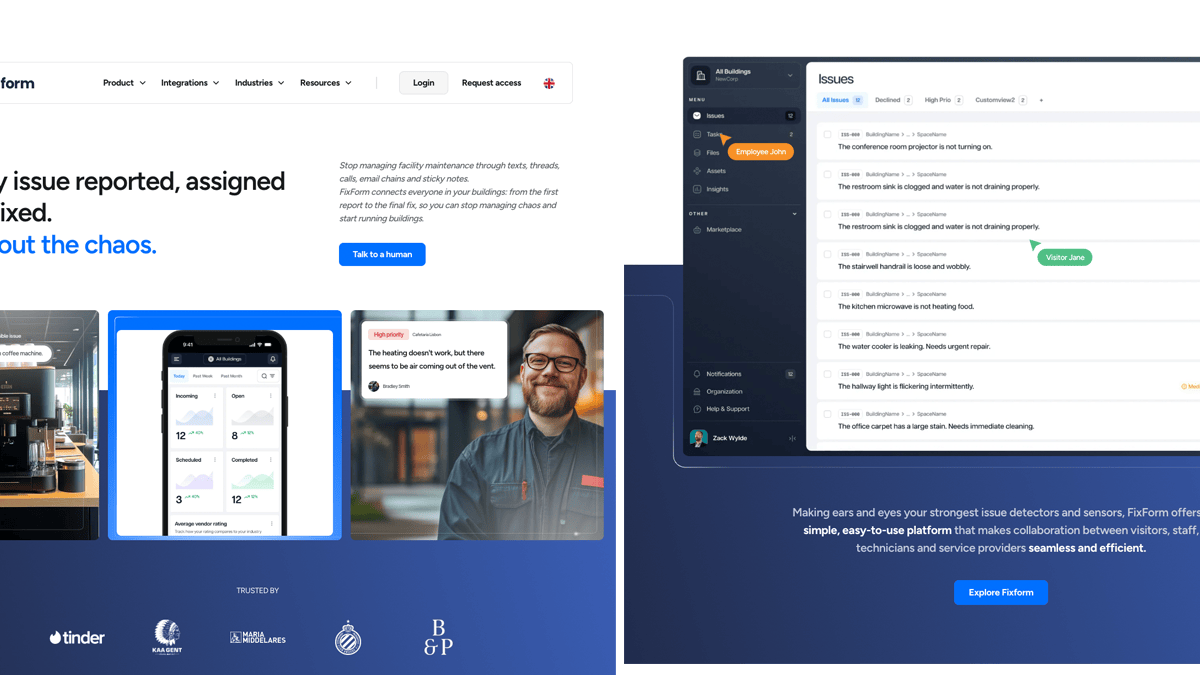
Fixform
Keeping buildings and spaces in good, safe and clean condition
After their technical co-founder departed unexpectedly, we stepped in with two staff engineers to build a quality-first MVP using Inertia.js, Vue, and Laravel. We established robust CI/CD pipelines, implemented comprehensive testing, and mentored the team through knowledge transfer.
Read case study
We help our clients succeed
You will not see companies like Amazon among our past clients. You will, however, see the names that will soon rock the SaaS world because we helped them predict risks and avoid failure.
“The madewithlove team works alongside us, treated our product with the love and attention it deserved and actively challenged us throughout the entire product development process.”
Michelle Dassen
Head of Product, Flexmail
“The staff engineers at madewithlove were essential in not only giving a diagnosis but also being involved to help deliver solutions.”

Dorian de Broqueville
General Manager, Izix
“I think what I also really valued about the collaboration was transparency and knowledge transfer. It needs to be a good fit with the company and the phase that the company is in.”

Thomas Vanhumbeeck
Cofounder & CEO, FixForm
FROM 150+ SAAS AUDITS
85% ship without automated testing
Manual QA dominates at every stage, seed to M&A.
Why QA becomes the bottleneckFROM 150+ SAAS AUDITS
2 in 3 SaaS teams skip code review
One engineer merges what another wrote. No second set of eyes.
The value of code reviewLatest insights
Our latest thinking on data engineering, AI integration, and building reliable ML systems.
We can help with your data & AI
Whether you need to build reliable AI features, fix your data pipeline, or help your team use AI effectively. We're ready to dig in.
Frequently asked questions
Everything you need to know about working with our data and AI engineers.
No. You need good enough data that is owned, understood and monitored. Perfection is a myth. Predictability is the goal.
Usually yes. We identify what is salvageable, what needs guardrails and what must be replaced. Most teams are not one rewrite away from salvation; they are one clear ownership model away.
The one your team can maintain. We choose tools based on your skills, constraints and long-term reality, not fashion. Python, Airflow, Spark, Snowflake or something simpler: the logo is never the point.
We help you define measurable quality thresholds, check for drift and establish pipelines that make data issues visible instead of silently passing incorrect signals into your model.
Yes. We look at your problem, the available signals, expected latency, accuracy needs and cost. Sometimes a simple model is enough. Sometimes you need RAG or vector search. Sometimes you need neither.
By setting clear rules. We help teams define what belongs to AI, what needs human review and how to keep codebases coherent when half the suggestions come from a model.
It ingests data reliably, rejects garbage, is reproducible end-to-end, has proper monitoring and makes failures loud. If it only works on one engineer's laptop, it is not healthy.
Yes. We work incrementally: stabilise the data, design a minimal pipeline, add monitoring and ship features in thin slices. You do not need a full AI overhaul to start delivering value.
The same way we measure data quality: with metrics, tests and evaluation loops. A demo that works once is not a quality signal. We make retrieval measurable and observable.
Yes. We plan our exit from day one. We document, pair-programme, build with your stack and transfer full ownership. No mysterious pipelines. No ghost systems. Your team keeps shipping long after we are gone.